


Vibe Coding and The Future of Media: I (Sort Of) Built An AI Fact-Checker
How I learned to stop worrying and love what artificial intelligence will do for journalism

A couple weeks ago, my friend Malcolm Ocean invited me to a skillshare to learn about Large Language Models (LLMs) — i.e., current emerging artificial intelligences — and making apps with LLMs. The skill of building apps using LLMs is now colloquially called “vibe coding.”
I did not expect to be so impressed. Now I want to share what I learned with you, because I feel like I’ve seen one slice of a really wild future.
Before I recount my vibe coding observations, let me give you some relevant context about my background. I’m not a programmer, but I am a very Internet Person. I have lots of Internet History and Internet Experimentation under my belt. I’ve done various forms of entrepreneurship and startup jobs, and I have carved out a respectable niche in media and technology. I care a lot about journalism and art, so I founded my own media organization and magazine. I’ve collaborated with media organizations that you’ve heard of and some you probably haven’t. I keep tabs on conversations about AI because I habitually keep tabs on conversations around these parts. But I’m far from an expert, and I haven’t worked in tech for the last few years, so that’s why I attended the skillshare.
A lot of programmers will already know what I’m talking about, but might find my process interesting anyway. With that said, if you already know what vibe coding is, then you might want to skip down to the section titled “Implications and Caveats.”
What Engineers Are Saying About Vibe Coding
Obviously, Silicon Valley is hyped about AI. But recently the tone has changed, partially because some software engineers fear for their job security. This is new. I’ve seen a softly growing panic about AI, and not just because people fear the broader implications of superintelligent AI (though many people are also afraid of that!).
To be clear, not all engineers are concerned about their job security, especially specialists and PhDs. But job security is becoming a common thread in the discourse. Also, the shift is not merely about AI replacing engineers; in some cases, the whole job of being an engineer is changing, as are engineer-adjacent jobs. A recently-leaked internal company memo from software company Shopify spelled this out; it explicitly says employees who think there’s good reason to hold out against the rising AI tide are in danger of losing their jobs. Similarly, the well-known programmer Steve Yegge, who has worked at places like Google and Amazon, recently wrote: “Time for your team to take the plunge, and start trying to stop writing code. That’s what LLMs are for.”
At Malcolm’s vibe coding skillshare, I saw a conversation that stuck with me. When this conversation happened, I was sitting on a couch in Malcolm’s living room, working on my laptop, and an engineer was seated nearby. I’ll call him Engineer #1. A friend of mine, Engineer #2, came in and sat with us. “What are you working on?” asked my friend. Engineer #1 showed us a map display that included interactive checkpoints from a road trip. “Cool, so that’s been your last couple hours?” asked Engineer #2. Engineer #1 said: “That’s been the last fifteen minutes.”
The night before, I went out to listen to music and ran into an old friend, a top-tier middle-aged programmer with work credits at famous tech companies; he helped me handle some website issues a few years ago. We caught up and he commented that I won’t need his help to handle issues anymore, noting: “You don’t need anyone’s help to prototype things anymore. You can build all kinds of apps on your own.” This is not someone I would expect to worry about job security, but he told me the incoming industry changes are endangering his job, even though he’s great at his job. “It used to be that if I quit my job, there was maybe a 5% chance I wouldn’t be able to get another job later. But now it’s 20%.”
These are potentially huge changes. I worry about the impact on my community. But can it be true that engineering no longer will bottleneck people like me? Here’s a quote from a recent piece on vibe coding in Frontier Magazine: “These systems will make talented creatives extremely productive, and they will dominate the software industry for the foreseeable future as far as I can tell.”
Okay Lydia, Cut To The Chase. What Did You Build At The Skillshare?
I’m going to tell you what I built and how, and I’ll show it to you, not because I think this is a market-ready product, but because I want you to see what I saw.
When I arrived at the skillshare, Malcolm asked what inspired me to attend. I explained that, although I got straight As in a C++ class decades ago and I know basic HTML, my professional history in tech is more like writing + media strategy + product design. Malcolm then asked if I had anything in mind to build. At first I couldn’t think of anything. Then I recalled a recurring conversation I’ve had with AI expert friends: AI might be able to help with fact-checking.
Maybe you are someone who thinks journalist fact-checking is useless. So let me tell you, I get it. One of the reasons I started my own magazine was that I have critiques of mainstream media framing assumptions and epistemology. Often an article has framing issues that are not about fact-checking, which nevertheless influence the reliability of information in an article. It’s easy to use true facts to build a narrative frame that seems superficially reasonable, but is actually terrible. It’s also easy to miss things because of innocent blind spots, but those innocent blind spots can be utterly infuriating for people who see what’s in the blind spot. Around 2021, I stopped reading the New Yorker for two years because of one article whose frame infuriated me, despite the fact that all its facts were true (I’m reading it again now, because in the end, it’s still an amazing magazine). So I understand why people have feelings about this!
Fact-checking is not a panacea. Nor is it an expression of ultimate truth. However, it is an important practice. Facts are a real thing, and they matter, even while framing issues also exist. And I have been grateful for fact-checking in the past, because sometimes I’m a subject of journalism, not just a creator of it! For instance: I don’t love the way I was portrayed when I got mentioned in Vanity Fair back in 2021, but I am very grateful to the VF fact-checking team, because the article almost claimed that I used to be a dominatrix, which is false, and this was corrected by the fact-checker. (It seems like people enjoy speculating that I was once a dominatrix, but my interest in women’s power + being a BDSM switch in my personal life is not equivalent to being a dominatrix; sorry guys.) The only reason the dominatrix notion didn’t end up in print was that the fact-checker caught it at the last minute, and she was able to do that because her professional intuition was good. Since people on the internet like to claim that I used to be a dominatrix, she could have been fooled if she hadn’t been good at her job.
So yeah, I love fact-checking and I love fact-checkers. However, the fact-checking process is expensive and slow. Aside from the big-name media organizations, most don’t do it. Even me! I’m guilty of not doing fact-checking sometimes, too! So far my magazine has not yet been professionally fact-checked because we didn’t have the money to pay for it (and I am painfully aware of several factual errors that we printed and caught too late). So, while I think it’s unlikely that AI will replace a professional fact-checker anytime soon, perhaps AI could supplement fact-checking, or maybe it can cover the basics so that indie magazines can afford to do more fact-checking.
Back to the skillshare. I explained all of this to Malcolm, and Malcolm was intrigued by the problem. We went back and forth discussing the steps involved in fact-checking, and Malcolm said that I should try writing a spec (i.e., a text document listing all the tasks that a fact-checking AI programs would do). Then I showed Malcolm an old New Yorker piece that describes the process of fact-checking. After we read through this piece together, Malcolm pointed out that it describes the process quite well, even without additional input from me. So, Malcolm suggested: Maybe we don’t have to write the spec ourselves; let’s see what happens if we give this article to Claude (one of the most popular AI agents, made by Anthropic) and then ask Claude to write the spec for us.
Malcolm helped me write the instructions for Claude, because Malcolm has more experience interacting with LLMs, so he understands how to talk to Claude better than I do — Malcolm “knows how the AI thinks.” When a person gives text instructions to an LLM, the instructions are called prompts. For our first prompt, we gave Claude the text from the New Yorker piece. Then we said:
I'm working on building a tool to help people do fact-checking with LLMs. Please pull out any key points and insights from this article about how a human fact-checker does their job.
Claude responded quickly. I reviewed Claude’s response and was impressed with its summary. I said as much to Malcolm. Malcolm then helped me write the next prompt:
How would you design an app for an LLM to fact-check an article?
And Claude wrote it out, step by step. It would have taken me a long time to write out all the steps to design this app; Claude did it in seconds. Importantly, Claude also did not miss anything big. Based on my previous knowledge of AI, I was assuming that I would need to correct at least one comically large error while doing this. But there weren’t any.
At this point we shifted gears, because Claude cannot build apps. But there are other LLMs, like Replit, that can build apps. (One of the testimonials on Replit’s website is from a user who says, “Replit helped me go from product manager to product creator.”) So then we said to Claude:
I am going to give a prompt to Replit. The prompt will tell Replit to build this app. Please write a detailed prompt that I can input into Replit, in order to build this app.
Here’s the spec Claude wrote in response.
So… then we gave Claude’s spec to Replit… and Replit built a web app in like, five minutes. Maybe it was ten minutes. I spent this time chatting with friends and playing with Malcolm’s new baby while Replit built the app, so Replit might have finished building the app faster than I realized. Regardless. Ten minutes!
Replit named the new fact-checking app FactCheckAI, or FactCheckPro. The initial build was followed by several further technical steps and hiccups. (I had to get an OpenAI key and give it to Replit; then there was an error, which Replit identified by itself, and when I asked Replit to fix the error, it did; then there was an unexpected unnecessary feature added to FactCheckAI, which was kind of interesting, but we removed it because it was distracting.) This entire process took less than an hour. At the end of the hour, here’s what we had:

I decided to test FactCheckAI on a piece of writing that I know extremely well: My recent post about the Peace Corps. I figured this would be a good test case, because I have personal experience and/or battle-tested professional knowledge about all the facts in the article, so I know the nuances of those facts. I fed some text from my Peace Corps post into FactCheckAI. It took a few minutes to “analyze claims:”
Within minutes, FactCheckAI came back with an itemized list of facts. Then it evaluated the truth of each fact, and provided links to specific sources so that I could follow up and check those sources directly if desired.
In many cases, FactCheckAI had trouble evaluating a given fact, which made sense. A lot of those were facts about me and my life. There were also facts that FactCheckAI had trouble verifying precisely because they were obscure, or because they weren’t stated in a way that matched the AI’s sense of precision. FactCheckAI generally assigned a low rate of accuracy to these facts, so the overall accuracy that FactCheckAI assigned my post was only 75%. This is a lot lower than the post’s real rate of accuracy, but with that said, it did an amazing job for a demo, and I was very grateful and impressed. (Thank you AI. I think you are great. Please don’t hurt me when you take over the world and turn everything into paperclips.)

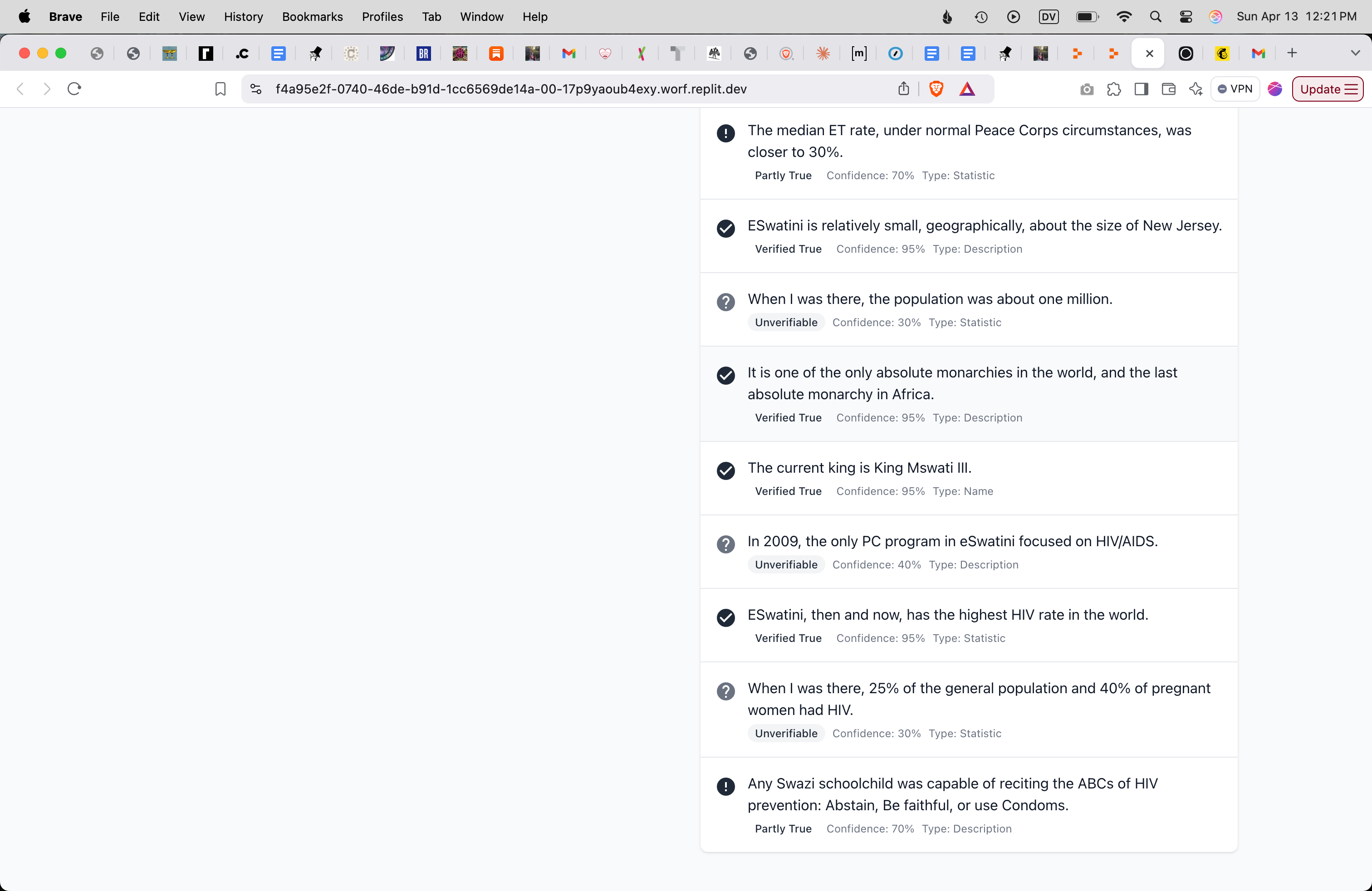
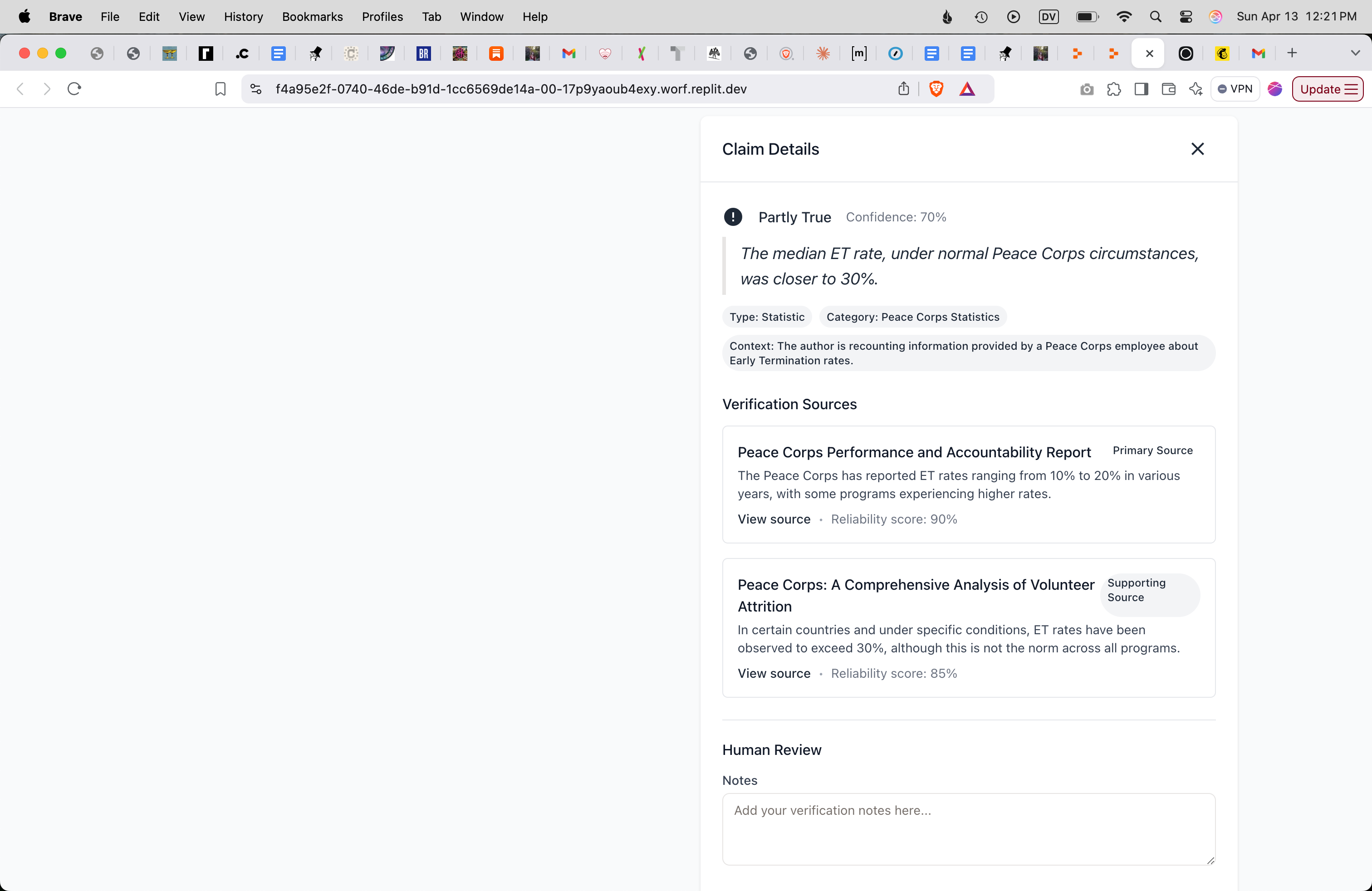
Let’s review a couple specific examples. In my original post, I stated that a Peace Corps employee had told me the maximum Early Termination rate they’d seen across Peace Corps programs was 50%; I also said the employee “explained that the median Early Termination rate, under normal Peace Corps circumstances, was closer to 30%.” (Early Termination is Peace Corps lingo for a volunteer going home early.) When FactCheckAI evaluated this claim, it used a Peace Corps Accountability Report that states “The Peace Corps has reported ET rates ranging from 10% to 20% in various years, with some programs experiencing higher rates,” and it also used a Comprehensive Analysis of Volunteer Attrition that states “In certain countries and under specific conditions, ET rates have been observed to exceed 30%, although this is not the norm across all programs.” After reviewing this evidence, it concluded that my claim might not be accurate.
Personally, if I was fact-checking my statement in the original post, then I would conclude it was true on the basis of these sources, because the sources support what I said even though they have a different emphasis. But when the AI looked at those sources, the AI only had 70% confidence in my original statements, or it labeled them “unverifiable.”
In another example, the AI verified my statements about the structure of HIV/AIDS education when I was in sub-Saharan Africa, but it couldn’t verify my precise claim that “Any Swazi schoolchild was capable of reciting the ABCs of HIV prevention: Abstain, Be faithful, or use Condoms.” So it gave the claim only 70% accuracy, which I think is too low.

Obviously, however, these are minor nitpicks. Because what the AI accomplished was amazing. I built FactCheckAI in an afternoon and it was able to go through an entire article, evaluate a ton of factual claims, and provide specific references for each evaluation. It performed its evaluation in minutes, and it mostly picked high-quality references too!
It is worth noting that I had to double-check the references it picked; the links provided by FactCheckAI in each source evaluation generally did not link to the documents it claimed to be referring to, so sometimes I had to take extra steps to track down the source; and I suspect that some of the references were “false positive” AI hallucinations, i.e., some of its references were probably made up. I didn’t check all of them, so I’m not sure what percentage was functional. With that said, when I double-checked the websites it linked to, the organizations I’d heard of were legitimate based on my experience, so at least it was pointing the user towards legitimate sources. Also, it’s interesting to note that Claude’s original spec included “safeguards against hallucinations.” The structure of FactCheckAI as designed by Replit, and the manner in which FactCheckAI provides citations and links, is how I had originally planned to design such a product; it makes sense if you are already aware of LLMs’ propensity to hallucinate; it seems the LLMs themselves are aware of this propensity, or at least, they can predict it well enough that they themselves included safeguards in this product.1
Now, as I said at the beginning of this post, FactCheckAI is not a market-ready product. It needs tons of fine-tuning. I’ve described some problems already, and here’s another one: The AI did not identify all the facts in the article, so it didn’t check all the facts within the text that it reviewed. Malcolm had an idea for fine-tuning this that would involve instructing FactCheckAI to chunk the article into paragraphs and review each paragraph very closely, but I had to go do an errand, so we didn’t get a chance to implement the change.
On my way out of the meetup, another guy suggested that I ask Replit to make documentation for FactCheckAI, so I did. Replit says that it made a readme file (a general overview), developer docs, a step-by-step setup guide, an API guide, and a user guide. If anyone would like these docs, just let me know where to send them. My only request is that you tell me what you do with them!
Thank you very much to everyone who helped me learn about this, including the AIs.
Implications and Caveats
What next?
I often get called a visionary by other people but rarely apply the label to myself because it’s literally impossible to take ten steps in San Francisco without running into someone who thinks they’re a visionary, and most of those people are boring. With that said, I feel comfortable saying that I’m typically ahead of the curve, and now I feel comfortable having opinions about vibe coding. Here’s what I think:
• This is, indeed, super powerful. But most people can’t do it yet. I could not have done what I described above without Malcolm’s help. I also brought a real skillset to the table. Most people aren’t me or Malcolm and don’t know anyone like me or Malcolm. Plus, even for us, it would take some serious tinkering to turn FactCheckAI into a good product. Afterwards, when I posted about vibe coding on Twitter/X, the user @not_a_hot_girl concurred: “the LLM requires a LOT of babysitting even for a very very tiny project, domain familiarity/expertise still helps a ton.” (I recommend clicking through to her full comment and quote tweets if you’re interested in the user experience elements of this conversation.)
• Timelines and predictions are so weird right now for so many reasons, but a big one is economic uncertainty, which will strongly affect AI. At Malcolm’s skillshare, I spent less than $10 on this experiment because all the tools involved have free versions except for the OpenAI API, which I had to put some cash into. I doubt that these conditions will last. So far, the big AI companies have not been prioritizing profit, but in the near future, they might be forced into it, because prices on everything are likely to go way up, including the computation power they rely on. This means that experimentation will become more costly, and perhaps the products will become less reliable.
• LLMs have real blind spots, and compensating for them will get harder as LLMs become more prevalent. Blind spots are no joke; threats like to lurk in blind spots. Black boxes, where users don’t know how something works, are also no joke. There are many historical and mythic examples of why it’s bad to become overly reliant on a black box; one of my favorites is from a science fiction book, the second novel in Cixin Liu’s Three-Body Trilogy. Liu tells the story of a space battle that is lost because no one on the spaceship understands how the superintelligent AI is making its decisions, so when something gets out of whack, the humans don’t notice it initially, and then they can’t fix it, so they die.
• Relatedly: There are probably startups built entirely with vibe coding now. I wonder if they’ll have to get rebuilt if those startups are successful and need to scale. (On the other hand, a lot of startups have to do that even when built by humans, so maybe it’s a wash.) Corollary: Something tells me that the biggest vulnerability of vibe coding is security, which won’t matter for tiny random apps, but will matter for a product that suddenly becomes widely used.
• Still, even accounting for these limitations, we are looking at a spectacular jump in human ability, especially as vibe coding is learned by people with new skillsets and then combined with other tools. I recently went to a bar night in San Francisco and observed that someone at the bar had 3D-printed a sparkly dildo with dinosaur legs. Obviously this is an absurd object; it is also evidence that people with the right equipment can, at this point, make whatever object comes into their head. Combine this with vibe coding and we have the powers of Olympic gods. Absent a civilizational collapse, people at a certain level of wealth and talent will create superhuman daemon assistants and fantastical artistic glories with a few small gestures, and this will happen in my lifetime. And of course, many of the less fortunate will be left behind.
• More prosaically, this is the first time in a long time that I’ve encountered a new technology where my immediate urge is to play around just to see what it can do, which I think is significant. Increasingly I hear about random playful stuff getting made that no one would have bothered making before. For example, I heard that about a month ago, some influencer used vibe coding to build an entire MMO (i.e. a multi-player video game). This was not a great video game or anything, but apparently enough people were briefly into it that its creator summarily sold $80k worth of in-game advertising. Another example: Last night at a dinner party, I ran into the up-and-coming tech writer Jasmine Sun, who was excited about vibe coding because she recently wanted to make a chart in Substack but couldn’t make the chart using the baseline Substack features, so she vibe coded a whole website (here’s the website: “A History of Definitions of Powerful AI”). So now, this question: What sorts of things do people randomly make on the internet now, and how will that become extensible, extended, and more fun?
• What happens when anyone can make a tiny yet highly complex program for any task connected to the internet, programmable objects, etc.? A lot of the time, individuals or communities want an app that doesn’t make sense as a full-on Silicon Valley startup funded by venture capital, and yet some of these apps could be game-changers. One of my favorite examples is a set of ideas that’s sometimes encapsulated by the phrase “personal Customer Relations Management (CRM).” In the business world, CRM software helps salespeople track relationships with sales targets, but it’s very expensive, and it has many features that only make sense for a large business. So among those of us who are aware that this software exists, we often find ourselves wanting similar software to help us manage our personal relationships, i.e. “personal CRM;” this especially makes sense for those of us who do things like run media organizations or host large gatherings. I became fascinated by personal CRM some years ago and I did a lot of research around it. But at the time I abandoned the field and open-sourced my research, hoping someone else could do something with it, because it turns out that even though lots of people want it, this is a Bermuda Triangle of startups, and I didn’t want to fly in there alone. (Here are my open-sourced notes on personal CRM, including some user interviews.) Sidenote: I’ve long thought that personal CRM could be integrated into other media more effectively, including journalism, and I suspect some cool experimentation around it will emerge soon.
I’m thrilled by the idea that this stuff might finally become real, and I’m excited to see how it combines and recombines.
• Update 5/4/25: Want more? I wrote a followup: “Vibe Coding, The Followup: Sneaky AI Hallucinations, Barefoot Developers, Et Cetera.”
Update, later in the day on 4/14: An earlier version of this post did not include this paragraph with caveats about hallucinated references, and details about what happened when I double-checked the references. I added this paragraph because I want to make it completely clear that, even if an LLM finds plausible references, a human currently needs to double-check them, because sometimes LLMs make stuff up. So, while an LLM can save time on fact-checking, you should not currently trust its references unless you or someone you trust double-checks those references.
I've been tracking this space as well, as I have some product ideas that I'd like to be able to make for myself and not spin up a whole startup. Thx for the summary. :D
BTW, I just stumbled onto https://openrouter.ai/ today as a way to use many different ai services but not get bogged down by a dozen subscriptions.
Brilliant. And thanks for introducing the Bermuda Triangle. I’ve flown and gotten lost in there as well.